线性回归
线性回归的基本要素
模型
为了简单起见,这里我们假设价格只取决于房屋状况的两个因素,即面积(平方米)和房龄(年)。接下来我们希望探索价格与这两个因素的具体关系。线性回归假设输出与各个输入之间是线性关系:
数据集
我们通常收集一系列的真实数据,例如多栋房屋的真实售出价格和它们对应的面积和房龄。我们希望在这个数据上面寻找模型参数来使模型的预测价格与真实价格的误差最小。在机器学习术语里,该数据集被称为训练数据集(training data set)或训练集(training set),一栋房屋被称为一个样本(sample),其真实售出价格叫作标签(label),用来预测标签的两个因素叫作特征(feature)。特征用来表征样本的特点。
损失函数
在模型训练中,我们需要衡量价格预测值与真实值之间的误差。通常我们会选取一个非负数作为误差,且数值越小表示误差越小。一个常用的选择是平方函数。 它在评估索引为 的样本误差的表达式为
优化函数 - 随机梯度下降
当模型和损失函数形式较为简单时,上面的误差最小化问题的解可以直接用公式表达出来。这类解叫作解析解(analytical solution)。本节使用的线性回归和平方误差刚好属于这个范畴。然而,大多数深度学习模型并没有解析解,只能通过优化算法有限次迭代模型参数来尽可能降低损失函数的值。这类解叫作数值解(numerical solution)。
在求数值解的优化算法中,小批量随机梯度下降(mini-batch stochastic gradient descent)在深度学习中被广泛使用。它的算法很简单:先选取一组模型参数的初始值,如随机选取;接下来对参数进行多次迭代,使每次迭代都可能降低损失函数的值。在每次迭代中,先随机均匀采样一个由固定数目训练数据样本所组成的小批量(mini-batch),然后求小批量中数据样本的平均损失有关模型参数的导数(梯度),最后用此结果与预先设定的一个正数的乘积作为模型参数在本次迭代的减小量。
学习率: 代表在每次优化中,能够学习的步长的大小
批量大小: 是小批量计算中的批量大小batch size
总结一下,优化函数的有以下两个步骤:
(i)初始化模型参数,一般来说使用随机初始化;
(ii)我们在数据上迭代多次,通过在负梯度方向移动参数来更新每个参数。
矢量计算
在模型训练或预测时,我们常常会同时处理多个数据样本并用到矢量计算。在介绍线性回归的矢量计算表达式之前,让我们先考虑对两个向量相加的两种方法。
向量相加的一种方法是,将这两个向量按元素逐一做标量加法。
向量相加的另一种方法是,将这两个向量直接做矢量加法。
笔记整理
实现顺序
- 生成数据集:随机标签,指定参数,计算标准结果添加噪声
- 定义模型
- 定义损失函数
- 定义优化模型
- 训练模型
- 设置超参,初始化模型参数
- 每次迭代中,小批量读取数据,初始化模型计算预测值,损失函数计算插值,反向传播求梯度,优化算法更新参数,参数梯度清零
- 数据集一般分为训练集、验证集、测试集
- 真实预测值称为label,用来预测标签的因素feature
- 预测结果偏差:损失函数(均方误差),可以直接求和多个样本
- 调整模型参数:优化函数(梯度下降,梯度反方向),迭代后损失函数值减小
Softmax与分类模型
Softmax逻辑回归模型是logistic回归模型在多分类问题上的推广,在多分类问题中,类标签y可以取两个以上的值。 Softmax回归模型对于诸如MNIST手写数字分类等问题是很有用的,该问题的目的是辨识10个不同的单个数字。Softmax回归是有监督的,不过后面也会介绍它与深度学习无监督学习方法的结合。
在机器学习尤其是深度学习中,softmax是个非常常用而且比较重要的函数,尤其在多分类的场景中使用广泛。他把一些输入映射为0-1之间的实数,并且归一化保证和为1,因此多分类的概率之和也刚好为1。
首先我们简单来看看softmax是什么意思。顾名思义,softmax由两个单词组成,其中一个是max。对于max我们都很熟悉,比如有两个变量a,b。如果a>b,则max为a,反之为b。用伪码简单描述一下就是if a > b return a; else b。
另外一个单词为soft。max存在的一个问题是什么呢?如果将max看成一个分类问题,就是非黑即白,最后的输出是一个确定的变量。更多的时候,我们希望输出的是取到某个分类的概率,或者说,我们希望分值大的那一项被经常取到,而分值较小的那一项也有一定的概率偶尔被取到,所以我们就应用到了soft的概念,即最后的输出是每个分类被取到的概率。
Softmax的定义^3
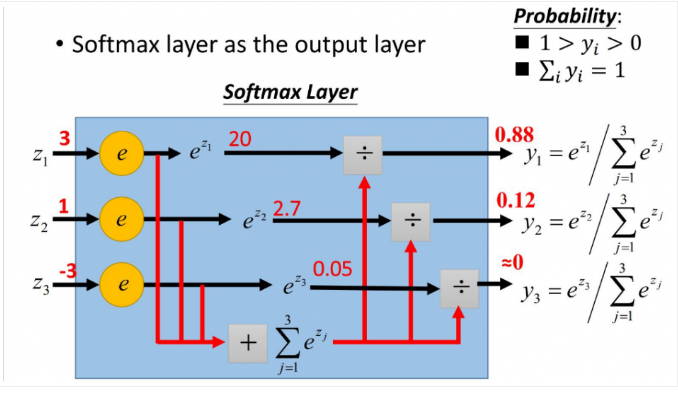
笔记整理
这是由于softmax函数的常数不变性,即softmax(x)=softmax(x+c),推导如下:
$$
softmax(x_i)=\frac{exp(x_i)}{\sum_jexp(x_j)}
$$
$$
(softmax(x+c))_i=\frac{exp(x_i+c)}{\sum_j exp(x_j+c)}=\frac{exp(c)exp(x_i)}{exp(c)\sum_jexp(x_j)}=\frac{exp(x_i)}{\sum_jexp(x_j)}=(softmax(x))_i
$$
上面的exp(c)之所以可以消除,是因为exp(a+b)=exp(a)*exp(b)这个特性将exp(c)提取出来了。
在计算softmax概率的时候,为了保证数值稳定性(numerical stability),我们可以选择给输入项减去一个常数,比如x的每个元素都要减去一个x中的最大元素。当输入项很大的时候,如果不减这样一个常数,取指数之后结果会变得非常大,发生溢出的现象,导致结果出现inf。
softmax函数是来自于sigmoid函数在多分类情况下的推广,他们的相同之处:
- 都具有良好的数据压缩能力是实数域R→[ 0 , 1 ]的映射函数,可以将杂乱无序没有实际含义的数字直接转化为每个分类的可能性概率。
- 都具有非常漂亮的导数形式,便于反向传播计算。
- 它们都是 soft version of max ,都可以将数据的差异明显化。
相同的,他们具有着不同的特点,sigmoid函数可以看成softmax函数的特例,softmax函数也可以看作sigmoid函数的推广。
- sigmoid函数前提假设是样本服从伯努利 (Bernoulli) 分布的假设,而softmax则是基于多项式分布。首先证明多项分布属于指数分布族,这样就可以使用广义线性模型来拟合这个多项分布,由广义线性模型推导出的目标函数即为Softmax回归的分类模型。
- sigmoid函数用于分辨每一种情况的可能性,所以用sigmoid函数实现多分类问题的时候,概率并不是归一的,反映的是每个情况的发生概率,因此非互斥的问题使用sigmoid函数可以获得比较漂亮的结果;softmax函数最初的设计思路适用于首先数字识别这样的互斥的多分类问题,因此进行了归一化操作,使得最后预测的结果是唯一的。
softmax基本概念
- 分类问题: 用来预测种类,图像识别,离散数值来表示不同类别
- 权重失量
- 神经网络图
单层神经网络,类别与变量间对应关系 - 输出问题
- 范围不确定
- 真实为离散值,输出不确定范围误差难以衡量
- softmax值变换为值为正和为1,不改变预测类别输出
- 小批量矢量计算
- 交叉熵,保证正确预测类别的值大
print(X.sum(dim=0, keepdim=True))#按相同列求和,保留列特征print(X.sum(dim=1, keepdim=True))#按相同行求和,保留行特征
多层感知机
多层感知器(MLP,Multilayer Perceptron)是一种前馈人工神经网络模型,其将输入的多个数据集映射到单一的输出的数据集上。

多层感知机在单层神经网络的基础上引入了一到多个隐藏层(hidden layer)。隐藏层位于输入层和输出层之间。
所示的多层感知机中,输入和输出个数分别为4和3,中间的隐藏层中包含了5个隐藏单元(hidden unit)。由于输入层不涉及计算,上图中的多层感知机的层数为2。由上图可见,隐藏层中的神经元和输入层中各个输入完全连接,输出层中的神经元和隐藏层中的各个神经元也完全连接。因此,多层感知机中的隐藏层和输出层都是全连接层。
具体来说,给定一个小批量样本$\boldsymbol{X} \in \mathbb{R}^{n \times d}$ ,其批量大小为 n ,输入个数为 d 。假设多层感知机只有一个隐藏层,其中隐藏单元个数为 h 。记隐藏层的输出(也称为隐藏层变量或隐藏变量)为 H ,有$\boldsymbol{H} \in \mathbb{R}^{n \times h}$ 。因为隐藏层和输出层均是全连接层,可以设隐藏层的权重参数和偏差参数分别为$\boldsymbol{W}_h \in \mathbb{R}^{d \times h}$和$\boldsymbol{b}_h \in \mathbb{R}^{1 \times h}$,输出层的权重和偏差参数分别为$\boldsymbol{W}_o \in \mathbb{R}^{h \times q}$和$\boldsymbol{b}_o \in \mathbb{R}^{1 \times q}$。
我们先来看一种含单隐藏层的多层感知机的设计。其输出$\boldsymbol{O} \in \mathbb{R}^{n \times q}$的计算为
$$
\begin{split}\begin{aligned}
\boldsymbol{H} &= \boldsymbol{X} \boldsymbol{W}_h + \boldsymbol{b}_h,\
\boldsymbol{O} &= \boldsymbol{H} \boldsymbol{W}_o + \boldsymbol{b}_o,
\end{aligned}\end{split}
$$
也就是将隐藏层的输出直接作为输出层的输入。如果将以上两个式子联立起来,可以得到
$$
\boldsymbol{O} = (\boldsymbol{X} \boldsymbol{W}_h + \boldsymbol{b}_h)\boldsymbol{W}_o + \boldsymbol{b}_o = \boldsymbol{X} \boldsymbol{W}_h\boldsymbol{W}_o + \boldsymbol{b}_h \boldsymbol{W}_o + \boldsymbol{b}_o.
$$
从联立后的式子可以看出,虽然神经网络引入了隐藏层,却依然等价于一个单层神经网络:其中输出层权重参数为$\boldsymbol{W}_h\boldsymbol{W}_o$,偏差参数为$\boldsymbol{b}_h \boldsymbol{W}_o + \boldsymbol{b}_o$。不难发现,即便再添加更多的隐藏层,以上设计依然只能与仅含输出层的单层神经网络等价。
笔记整理
多层感知机中最为重要的自然是“多层”,多层中涉及到的隐藏层的目的是为了将线性的神经网络复杂化,更加有效的逼近满足条件的任何一个函数。
因此文中先证明了一个最常见的思路,即两个线性层复合,是不可行的,无论多少层线性层复合最后得到的结果仍然是等价于线性层。这个结果的逻辑来自与线性代数中,H=XW+b 是一个仿射变换,通过W变换和b平移,而O=HW2+b2 则是通过W2变换和b2平移,最终经过矩阵的乘法和加法的运算法则(分配律)得到最终仍然是对X的仿射变换。
在线性层复合不行的情况下,最容易想到的思路就是将隐藏层变成非线性的,即通过一个“激励函数”将隐藏层的输出改变。
因此这里主要讨论一下,为什么添加激励函数后可以拟合“几乎”任意一个函数。
将函数分成三类:逻辑函数,分类函数,连续函数(分类的原则是输入输出形式)
- 通过一个激励函数可以完成简单的或与非门逻辑,因此通过隐藏层中神经元复合就可以完成任何一个逻辑函数拟合。只需要通过神经网络的拟合将真值表完全表示
- 通过之前使用的线性分类器构成的线性边界进行复合便可以得到任意一个分类函数。
- 通过积分微元法的思想可以拟合任何一个普通的可积函数
Epoch, Batch, Iteration
深度学习的优化算法,说白了就是梯度下降。每次的参数更新有两种方式。
第一种,遍历全部数据集算一次损失函数,然后算函数对各个参数的梯度,更新梯度。这种方法每更新一次参数都要把数据集里的所有样本都看一遍,计算量开销大,计算速度慢,不支持在线学习,这称为Batch gradient descent,批梯度下降。
另一种,每看一个数据就算一下损失函数,然后求梯度更新参数,这个称为随机梯度下降,stochastic gradient descent。这个方法速度比较快,但是收敛性能不太好,可能在最优点附近晃来晃去,hit不到最优点。两次参数的更新也有可能互相抵消掉,造成目标函数震荡的比较剧烈。
为了克服两种方法的缺点,现在一般采用的是一种折中手段,mini-batch gradient decent,小批的梯度下降,这种方法把数据分为若干个批,按批来更新参数,这样,一个批中的一组数据共同决定了本次梯度的方向,下降起来就不容易跑偏,减少了随机性。另一方面因为批的样本数与整个数据集相比小了很多,计算量也不是很大。
现在用的优化器SGD是stochastic gradient descent的缩写,但不代表是一个样本就更新一回,还是基于mini-batch的。
那 batch epoch iteration代表什么呢?
- batchsize:批大小。在深度学习中,一般采用SGD训练,即每次训练在训练集中取batchsize个样本训练;
- iteration:1个iteration等于使用batchsize个样本训练一次;
- epoch:1个epoch等于使用训练集中的全部样本训练一次,通俗的讲epoch的值就是整个数据集被轮几次。
比如训练集有500个样本,batchsize = 10 ,那么训练完整个样本集:iteration=50,epoch=1.
batch: 深度学习每一次参数的更新所需要损失函数并不是由一个数据获得的,而是由一组数据加权得到的,这一组数据的数量就是batchsize。
batchsize最大是样本总数N,此时就是Full batch learning;最小是1,即每次只训练一个样本,这就是在线学习(Online Learning)。当我们分批学习时,每次使用过全部训练数据完成一次Forword运算以及一次BP运算,成为完成了一次epoch。
mnist 数据集有 60000 张图片作为训练数据,10000 张图片作为测试数据。假设现在选择 Batch Size = 100 对模型进行训练。迭代30000次。
每个 Epoch 要训练的图片数量:60000(训练集上的所有图像)
- 训练集具有的 Batch 个数: 60000/100=600
- 每个 Epoch 需要完成的 Batch 个数: 600
- 每个 Epoch 具有的 Iteration 个数: 600(完成一个Batch训练,相当于参数迭代一次)
- 每个 Epoch 中发生模型权重更新的次数:600
- 训练 10 个Epoch后,模型权重更新的次数: 600*10=6000
- 不同Epoch的训练,其实用的是同一个训练集的数据。第1个Epoch和第10个Epoch虽然用的都是训练集的60000图片,但是对模型的权重更新值却是完全不同的。因为不同Epoch的模型处于代价函数空间上的不同位置,模型的训练代越靠后,越接近谷底,其代价越小。
- 总共完成30000次迭代,相当于完成了 30000/600=50 个Epoch
笔记整理
训练集、验证集和测试集的比例应该怎么去进行分配呢?
传统上是6:2:2的比例,但是不同的情况下你的选择应当不同。这方面的研究也有很多,如果你想要知道我们在设置比例的时候应当参考那些东西,可以去看Isabelle Guyon的这篇论文:A scaling law for the validation-set training-set size ratio 。他的个人主页(http://www.clopinet.com/isabelle/)里也展示了他对于这个问题的研究。训练集、验证集和测试集的数据是否可以有所重合?
有些时候我们的数据太少了,又不想使用数据增强,那么训练集、验证集和测试集的数据是否可以有所重合呢?这方面的研究就更多了,各种交叉方法,感兴趣的话可以去看Filzmoser这一篇文章Repeated double cross validationtorch.mm 和 torch.mul 的区别?
torch.mm是矩阵相乘,torch.mul是按元素相乘torch.manual_seed(1)的作用?
设置随机种子,使实验结果可以复现optimizer.zero_grad()的作用?
使梯度置零,防止不同batch得到的梯度累加为什么选择的激活函数普遍具有梯度消失的特点?
开始的时候我一直好奇为什么选择的激活函数普遍具有梯度消失的特点,这样不就让部分神经元失活使最后结果出问题吗?后来看到一篇文章的描述才发现,正是因为模拟人脑的生物神经网络的方法。在2001年有研究表明生物脑的神经元工作具有稀疏性,这样可以节约尽可能多的能量,据研究,只有大约1%-4%的神经元被激活参与,绝大多数情况下,神经元是处于抑制状态的,因此ReLu函数反而是更加优秀的近似生物激活函数。
所以第一个问题,抑制现象是必须发生的,这样能更好的拟合特征。
那么自然也引申出了第二个问题,为什么sigmoid函数这类函数不行?
- 中间部分梯度值过小(最大只有0.25)因此即使在中间部分也没有办法明显的激活,反而会在多层中失活,表现非常不好。
- 指数运算在计算中过于复杂,不利于运算,反而ReLu函数用最简单的梯度
在第二条解决之后,我们来看看ReLu函数所遇到的问题, - 在负向部分完全失活,如果选择的超参数不好等情况,可能会出现过多神经元失活,从而整个网络死亡。
- ReLu函数不是zero-centered,即激活函数输出的总是非负值,而gradient也是非负值,在back propagate情况下总会得到与输入x相同的结果,同正或者同负,因此收敛会显著受到影响,一些要减小的参数和要增加的参数会受到捆绑限制。
这两个问题的解决方法分别是 - 如果出现神经元失活的情况,可以选择调整超参数或者换成Leaky ReLu 但是,没有证据证明任何情况下都是Leaky-ReLu好
- 针对非zero-centered情况,可以选择用minibatch gradient decent 通过batch里面的正负调整,或者使用ELU(Exponential Linear Units)但是同样具有计算量过大的情况,同样没有证据ELU总是优于ReLU。
所以绝大多数情况下建议使用ReLu。
pytorch内的函数
torch.ones()/torch.zeros(),与MATLAB的ones/zeros很接近。初始化生成
均匀分布
torch.rand(sizes, out=None) → Tensor
返回一个张量,包含了从区间[0, 1)的均匀分布中抽取的一组随机数。张量的形状由参数sizes定义。
标准正态分布
torch.randn(sizes, out=None) → Tensor
返回一个张量,包含了从标准正态分布(均值为0,方差为1,即高斯白噪声)中抽取的一组随机数。张量的形状由参数sizes定义。
torch.mul(a, b)是矩阵a和b对应位相乘,a和b的维度必须相等,比如a的维度是(1, 2),b的维度是(1, 2),返回的仍是(1, 2)的矩阵
torch.mm(a, b)是矩阵a和b矩阵相乘,比如a的维度是(1, 2),b的维度是(2, 3),返回的就是(1, 3)的矩阵
torch.Tensor是一种包含单一数据类型元素的多维矩阵,定义了7种CPU tensor和8种GPU tensor类型。
random.shuffle(a):用于将一个列表中的元素打乱。shuffle() 是不能直接访问的,需要导入 random 模块,然后通过 random 静态对象调用该方法。
backward()是pytorch中提供的函数,配套有require_grad:
1.所有的tensor都有.requires_grad属性,可以设置这个属性.x = tensor.ones(2,4,requires_grad=True)
2.如果想改变这个属性,就调用tensor.requires_grad_()方法: x.requires_grad_(False)